If you have mostly worked with Large Language Models (LLMs) or Supervised Learning, RL is a shift in mindset:
- Supervised Learning (like predicting the next token in a text file or classifying an image) relies on a static dataset of static correct answers.
- Reinforcement Learning relies on active feedback loops. An Agent (our AI model) interacts with an Environment (the game or simulation). It takes an Action, receives an Observation (the new state of the environment) and a Reward (a signal telling the agent how well it is doing), and repeats.
The agent’s goal is to learn a Policy (a mapping from observations to actions) that maximizes the cumulative reward over time. It starts completely random and improves purely through trial and error.
Because there is no “correct answer” provided upfront, RL agents often find incredibly clever, emergent ways to solve games that developers never anticipated. However, this trial-and-error process is computationally intensive and requires millions of interactions, which is why bringing it directly to the browser is both challenging and exciting.
Reinforcement Learning (RL) has always been one of the most fascinating branches of AI. There is something deeply satisfying about watching a blank-slate agent explore an environment and gradually emerge with a superhuman policy.
Yet, compared to the explosive growth of LLM playgrounds and tools, RL remains relatively inaccessible. Setting up a local environment often means wrestling with Python virtual environments, CUDA versions, PyTorch installations, and headless rendering bugs in Gymnasium.
We built Agenlus to solve this. It is a community platform and model hub for Reinforcement Learning designed to run entirely in the browser—no installation, no CUDA configuration, just instant training and evaluation.
Democratizing Reinforcement Learning
For the past decade, state-of-the-art Reinforcement Learning has been the exclusive playground of elite corporate labs and well-funded academic institutions. Whether it is Google DeepMind’s AlphaGo, OpenAI’s Dota 2 bots, or sophisticated industrial robotics control, RL has required access to massive compute clusters, complex simulator setups, and specialized mathematical expertise.
This centralization has stifled the creative potential of independent developers and researchers. While anyone can easily prompt a large language model online, starting out with RL requires wrestling with complex local setups, GPU drivers, and local virtualization, only to wait hours for a simple agent to converge.
We believe RL needs to be democratized.
By leveraging modern web technologies, we want to break down these barriers:
- Lowering the Entry Barrier: You don’t need a high-end local machine or an AWS budget to experiment with RL. If you have a browser, you have a fully functional RL research lab.
- Open-Source Environment Sharing: Just as Hugging Face democratized NLP by making models easy to share, Agenlus allows developers to upload, share, and benchmark environments instantly.
- Interactive Learning: Seeing the training process happen live in the browser builds a deep, intuitive understanding of how agent policies adapt to rewards.
By putting the tools of RL directly into the hands of the global developer community, we aim to accelerate the discovery of novel control architectures and algorithms that corporate labs might overlook.
Why B2C RL is Highly Viable Today
We are currently witnessing immense compute inflation dominated by LLMs. This has made building B2C AI startups incredibly expensive, forcing founders to choose between paying massive cloud GPU invoices or raising millions in venture capital.
We believe Reinforcement Learning (RL) is structurally primed to break this cycle and lead a new wave of highly profitable B2C AI applications for three key reasons:
- Zero Marginal Infrastructure Cost: Unlike LLMs where every inference token costs API credits, RL training and inference in Agenlus run 100% locally on the user’s client hardware via WebGPU. Our server costs are virtually zero. This allows us to scale to millions of active users and offer a permanent free tier without burning through compute credits, shifting the monetization focus to marketplace transactions and custom assets.
- Extreme Model Efficiency: While a decent LLM requires billions of parameters, high-performing RL agents for games (even complex 2D/3D platformers and control tasks) are incredibly lightweight. A small Multi-Layer Perceptron (MLP) or a tiny Convolutional Neural Network (CNN) of under 100K parameters is often enough to achieve superhuman policies. These models load instantly and execute hundreds of steps per second on entry-level mobile devices or laptops.
- Gamification and Natural Viral Loops: Generative AI tools are mostly focused on productivity. In contrast, training an RL agent is inherently gamified. It feels like nurturing a digital pet (like a Tamagotchi) or coaching a sports team. By transitioning the agent from direct control to autonomic training, users develop a deep emotional attachment to their agent’s playstyle. When you add competitive leaderboards and multi-agent PvP arenas, you create a natural, viral social loop (“My agent can beat yours”) that drives organic growth without expensive customer acquisition costs.
- Crowdsourcing the Future of Offline Data: RL’s biggest bottleneck in industries like robotics is the lack of diverse, high-quality demonstration datasets. By building a B2C platform where users play to train agents, we are crowdsourcing a massive library of human behavioral trajectories across thousands of environments. This diverse dataset is a goldmine for training future foundational models that generalize across multiple control domains.
See It in Action
Here is a quick YouTube demonstration of the platform in action:
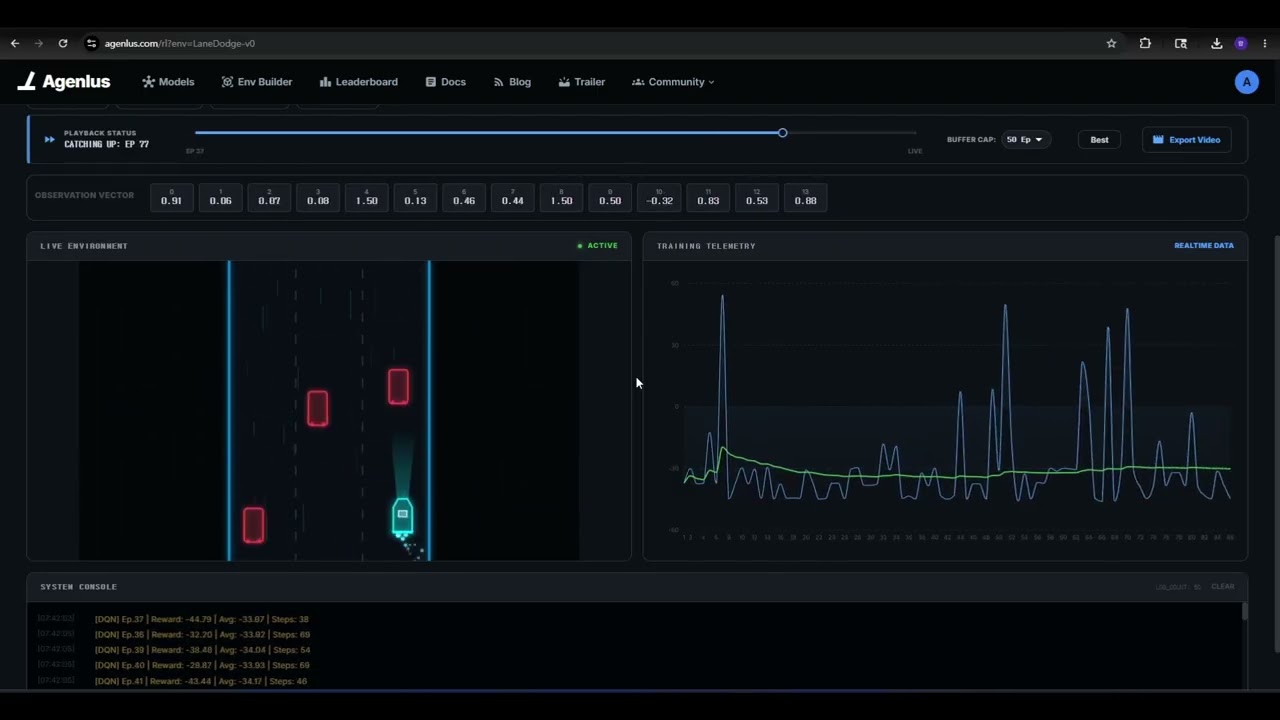
And here is a preview of the web UI running a client-side training loop:
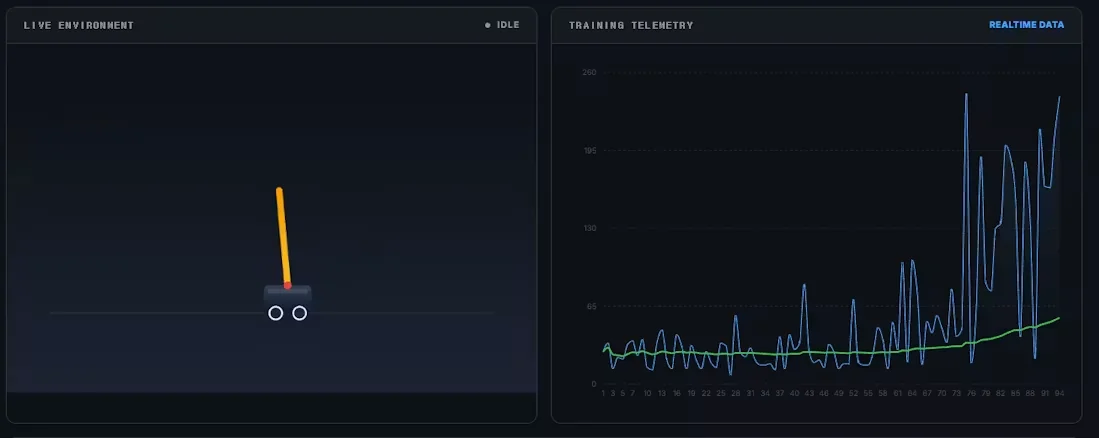
Here is how we built the architecture to make in-browser RL viable, the UX challenges we encountered, and why we believe RL is prime for a B2C comeback.
The Architecture: WebGPU + Pyodide + Web Worker
To achieve a zero-install experience, we had to move both the environment simulation and the model training into the client browser.
Our core architecture splits the load into three parts:
Browser Context
├── Web Worker (Pyodide)
│ ├── gymnasium (micropip)
│ ├── env.step(action) -> observation, reward, terminated
│ └── Sends state updates to the main thread
│
├── Main Thread (WebGPU & JS)
│ ├── Model inference & policy updates
│ ├── Action selection (via WebGPU-accelerated tensors)
│ └── Drawing Commands Bridge (rendering to Canvas)
1. Pyodide in a Web Worker
We use Pyodide (Python compiled to WebAssembly) to run official gymnasium environments like CartPole and MountainCar.
Running Python environments in the browser can easily freeze the UI because Python execution is single-threaded. By offloading Pyodide to a dedicated Web Worker, we keep the main UI thread running at a smooth 60fps.
2. Main Thread for WebGPU Inference & Drawing Commands Bridge
We utilize WebGPU on the main thread for neural network updates and forward passes.
Because the observation state returned by Pyodide is simple (e.g., 4 float values for CartPole), passing data between the Web Worker and the WebGPU context has negligible serialization overhead.
For environment visualization, standard Gymnasium environments rely heavily on Pygame, which cannot render directly to a browser Canvas and introduces massive performance overhead if we pass raw pixel frame buffers (rgb_array) back and forth from WASM.
To bypass this, we built a Pygame Mocking Bridge in Pyodide:
- We intercept all
pygame.drawcalls (likerect,circle,line) in the Python environment by injecting a mockpygamemodule dynamically. - The mock module translates Python drawing operations into a list of lightweight JSON drawing commands (e.g.,
{"type": "circle", "color": [255, 0, 0], "center": [100, 50], "radius": 10}). - These instructions are sent from the Web Worker to the main thread, where native HTML5 Canvas draws them.
This compromise preserves complete compatibility with standard Gymnasium environment rendering codes (import pygame inside the environment still works) while keeping the graphics pipeline lightning fast and hardware-accelerated.
Overcoming Browser Constraints
Building a fully client-side ML training loop comes with unique friction points. Here is how we addressed them:
1. The 15-Second Pyodide Cold Start
Loading Pyodide, initializing the Python runtime, and installing dependencies via micropip (like numpy and scipy) can take anywhere from 10 to 30 seconds depending on the user’s connection.
To hide this latency:
- Background Preloading: We spin up the Web Worker and start loading Pyodide in the background the moment a user lands on the platform, even while they are just browsing the catalog of environments.
- Service Worker Caching: Once loaded, WASM binaries and pip packages are aggressively cached via IndexedDB/Cache API so subsequent visits load instantly.
2. Session Persistence (Handling Tab Closes)
Unlike server-side training, if a user closes their browser tab, they risk losing their active training progress. Currently, we save basic training metadata (such as total episodes, training steps, and best reward) as well as local demonstration logs to the browser’s localStorage for progress tracking. To solve the problem of losing active model states, our immediate next step is to implement automatic agent checkpointing (saving model weights and hyperparameters) to IndexedDB, allowing users to seamlessly resume active training sessions even after a tab close or crash.
The Core Loop: Imitation Learning as a Gateway
A major roadblock in RL is sample inefficiency: an agent can take thousands of episodes just to learn how to balance a pole. For a casual user in a browser, waiting 10 minutes for any sign of intelligence is a retention killer.
We designed a dual-mode interaction loop to fix this:
- Human Demonstration (Direct Control): Users can directly play the game using their keyboard/mouse to generate demonstration trajectories.
- Imitation Learning (Behavioral Cloning): We use these human demonstrations to train a base model instantly. The agent immediately mirrors the player’s playstyle.
- RL Fine-Tuning: Once the agent has a basic grasp of the task, the user hands over control to the RL algorithm (PPO, DQN) to optimize the policy beyond human performance.
This “human-in-the-loop” approach solves the cold-start problem of training from scratch and gives users a strong sense of ownership: “This agent is learning to play like me, but better.”
What’s Next? The Grand Vision
We don’t view Agenlus as just a browser game platform. Our ultimate goal is to build the foundational infrastructure for the next generation of physical control AI.
Our roadmap spans three major phases of expansion:
1. A Modular Sandbox for Physics and Control (Medium-Term)
We are building a low-code, web-based sandbox studio where creators can design custom 2D/3D environments with complex physics, import them with a single click, and define custom reward systems. By democratizing environment creation, we want to scale from a few classic control tasks to thousands of community-generated physical challenges.
2. Sim-to-Real: The Robotics Bridge (Long-Term)
Training robots in the physical world is slow, dangerous, and expensive. Simulators are the only viable path forward. Because Agenlus agents are trained and exported in standard formats (like ONNX and TensorFlow.js models) directly from the browser, we are building a seamless deployment pipeline to physical hardware. In the future, you will be able to train an autonomous drone control policy or a robotic arm manipulator inside an Agenlus browser tab, and deploy that exact policy over-the-air (OTA) to a physical robot (such as a Raspberry Pi or micro-controller) in seconds.
3. The Foundation Model for Physical Control
By crowdsourcing human demonstration trajectories (via our imitation learning loop) and parallelizing WebGPU training runs across our global user base, we aim to compile the largest public offline dataset of physical interactions. We want to use this data to train a Generalist Foundation Model for Physical Control—an agent that inherently understands gravity, friction, momentum, and spatial mechanics, allowing it to adapt to any physical environment or robotic hardware with zero-shot generalization.
We would love to get your feedback on our architecture and approach. How would you design client-side RL differently? What environments would you like to see trained in a browser?
Check out the project: Agenlus.com
]]>